marc数据读取 日期:2023-01-06 人气:611 无论使用什么语言读或写`marc`数据,都必须吃透marc的数据格式。如果是cnmarc的格式,强烈建议参考《中国机读目录格式使用手册》,这本书对格式的讲解很详细。 读取,就分2步,一读,一取。 读:marc数据文件后缀为.mrc,是.iso格式的文本,每一条记录为一行,有一个结束符chr(29)。所以可以一行一行的读取数据。 取:先获取记录头标区和地址目次区的信息,然后根据地址目次区的位置地址去切割。其中字段分隔符chr(30),子字段标识符chr(31) 为了人性化阅读,人为的定义如下替代符号: ``` $--------chr(31) @--------chr(30) %--------chr(29) #--------space ``` #### 头标区 固定24位,每一位都有其含义,注意空格不能少哦。。 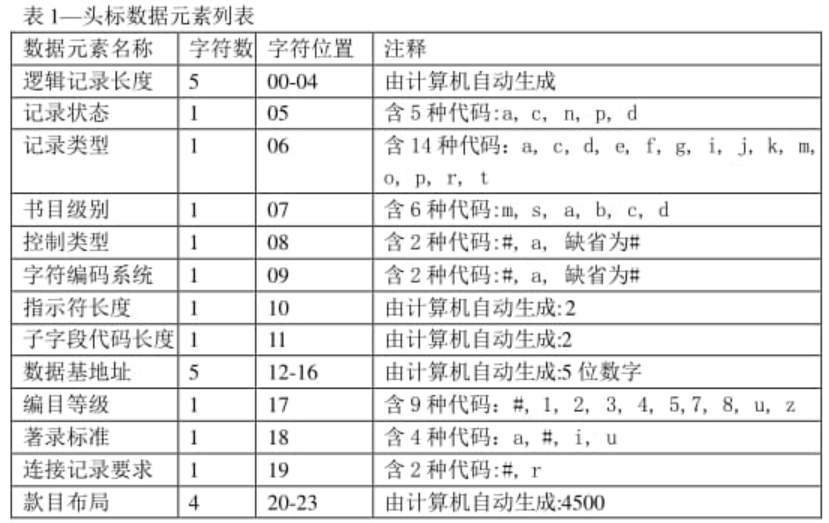 例如,为头标区:01071nam0#2200277###450#,逐位解析: - 01071: 记录总长,5位。 > 记录长度跟字符编码有关系,一般有gbk中文字符集,还有unicode大字符集。marc文件如果保存成gbk文本的话,计算长度的时候,中文2位,西文1位,unicode编码的话,中西文都是按2位算 - nam0: 如果是丛书(有225字段),就是oam2,每一位都有具体的意思。还有其他变化。这是常用的。 - 22: 一般是22,具体的意思可以查书。 - 00277: 数据字段区以前的字符总长度,5位。 - 450: 一般是450,具体的意思可以查书。 #### 地址目次区 由若干目次项和位于目次区末的字段分隔符组成。每个字段都会在目次区中有一个对应的目次项,因此,目次区内目录的数量取决于数据区内字段的数量。每个目次项的长度为12个字符,数据区中的每个字段在目次区中都对应有一个长度为12个字符的目录,目次区的总长度为12N(N为数据区内字段的个数)。在这12个字符中,前3位是字段标识符,中间4位表示该字段长度,后5位表示该字段起始位置。 便于阅读人为添加分隔符`;`和`,`,例如: 001,0013,00000;005,0017,00013;…………………………801,0022,00771@ - 001,0013,00000: 表示字段001(3位),字符长度0013(4位),在数据字段区开始的位置00000(5位) - 801,0022,00771: 表示字段801,字符长度0022,在数据字段区开始的位置:00771 这里是读取数据的一个重要目录,知道了这个规则,很容易把每条数据分割出来,因为每个数据规则都是固定长度的。 #### 数据字段区 数据区是著录目录数据的区域,由若干数据字段如档号、题名、责任者等组成,是MRAC记录的核心部分。数据区字段设置的依据主要是《档案著录规则》。数据区中的每条数据字段相当于手工著录的每个著录项目。 每个字段(00-字段除外)均由两个指示符以及随其后的任意数目的子字段组成。机读目录用三位数字来标识字段,因此,每条记录最多可有999个字段。  字段间使用`@`分隔,子字段使用`$`分割。 例如: 012001022343@20020928000000.0@##$a7-80142-191-4$dCNY46.00@…………………………………………@% - @##$: 这里##就是指示符位置。如,101字段的指示符为01,那么就写作: @01$ > 另外需要注意的是分割符号`@`为前面字段的长度 ### 鸣谢 - [走看看](http://t.zoukankan.com/twilight-p-1330344.html) - [挂云帆](https://www.guayunfan.com/baike/855496.html) - [csdn**lifan5**](https://blog.csdn.net/lifan5/article/details/21167803?locationNum=2) - [文库吧](https://www.wenkub.com/doc-21140027.html) 标签: marc 编目 图书管理 上一篇:mysql权限管理命令 下一篇:PHP 函数strlen()与mb_strlen()的区别 随便看看 2026-01-08 如何使用mvn命令导入依赖 2026-01-07 mysql权限管理命令 2025-12-30 哎和唉的区别在哪 2025-12-30 印章小知识——各部分名称 2025-12-15 明初大移民的影响 留言